
Amazon Redshift Serverlessを触ってみた(Redshift query editor v2)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
AWS re:Invent 2021でAmazon Redshift Serverlessが発表されました。
この名前の通りAWSのデータウェアハウスサービスであるAmazon Redshiftがサーバーレスとなり、クラスターの管理が不要、使用量に応じた課金となりました。
今回は、このAmazon Redshift Serverless(プレビュー)を触ってみました。
やってみる
環境の作成
Redshiftのコンソールで[Try Amazon Redshift Serverless (Preview)]をクリックします。

[Get started with Amazon Redshift Serverless (Preview)]画面が開きます。ここでRedshift Serverlessの環境を作成できます。
まず[Get started with Serverless credit]ではサーバーレスクレジットの使用を設定します。ここで[Choose starter base configuration]を選択すると、ベースRPU(Redshift Processing Units)レベルが低い設定で利用を開始できるためサーバーレスクレジットの消費を節約できます。また$500.00分のクレジットが付与されます。このクレジットを使い切るとデータベースが自動で削除されるとのことなので課金の心配なくプレビューを試用できますね。
また[Configuration]では作成されるリソースなどが確認できます。データベース、管理者ユーザークレデンシャル、VPC、セキュリティグループ、サブネットなどをよろしく作ってくれるようです。このマネージドさが流石サーバーレスですね。
[Create serverless endpoint]をクリックします。
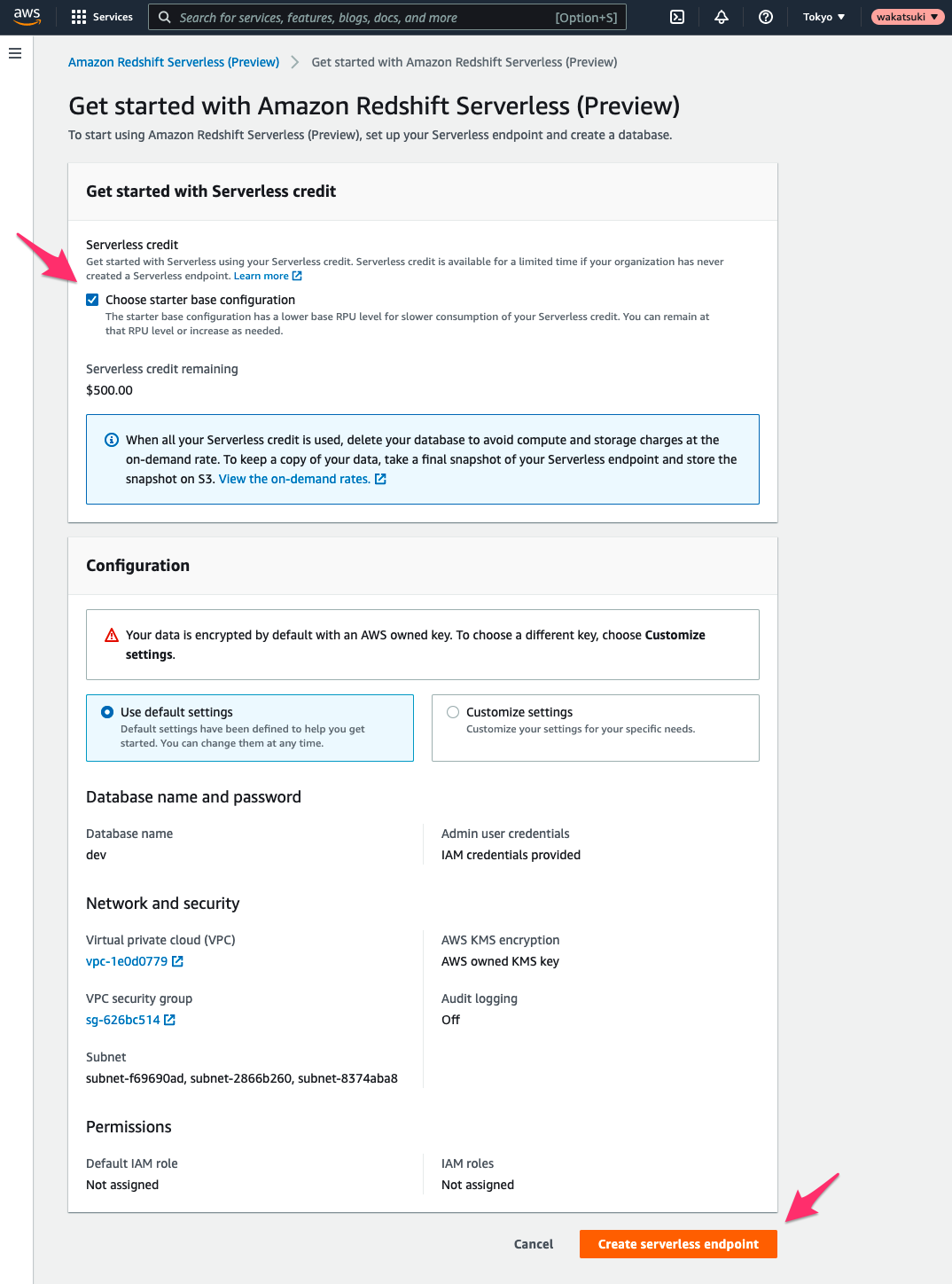
エンドポイントの作成が開始されます。

数分待つと完了しました。データベースが1つ作成されているようです。

Redshift query editor v2を使ってみる
それでは作成した環境を使用してデータのクエリをしてみます。[Query data]をクリックします。
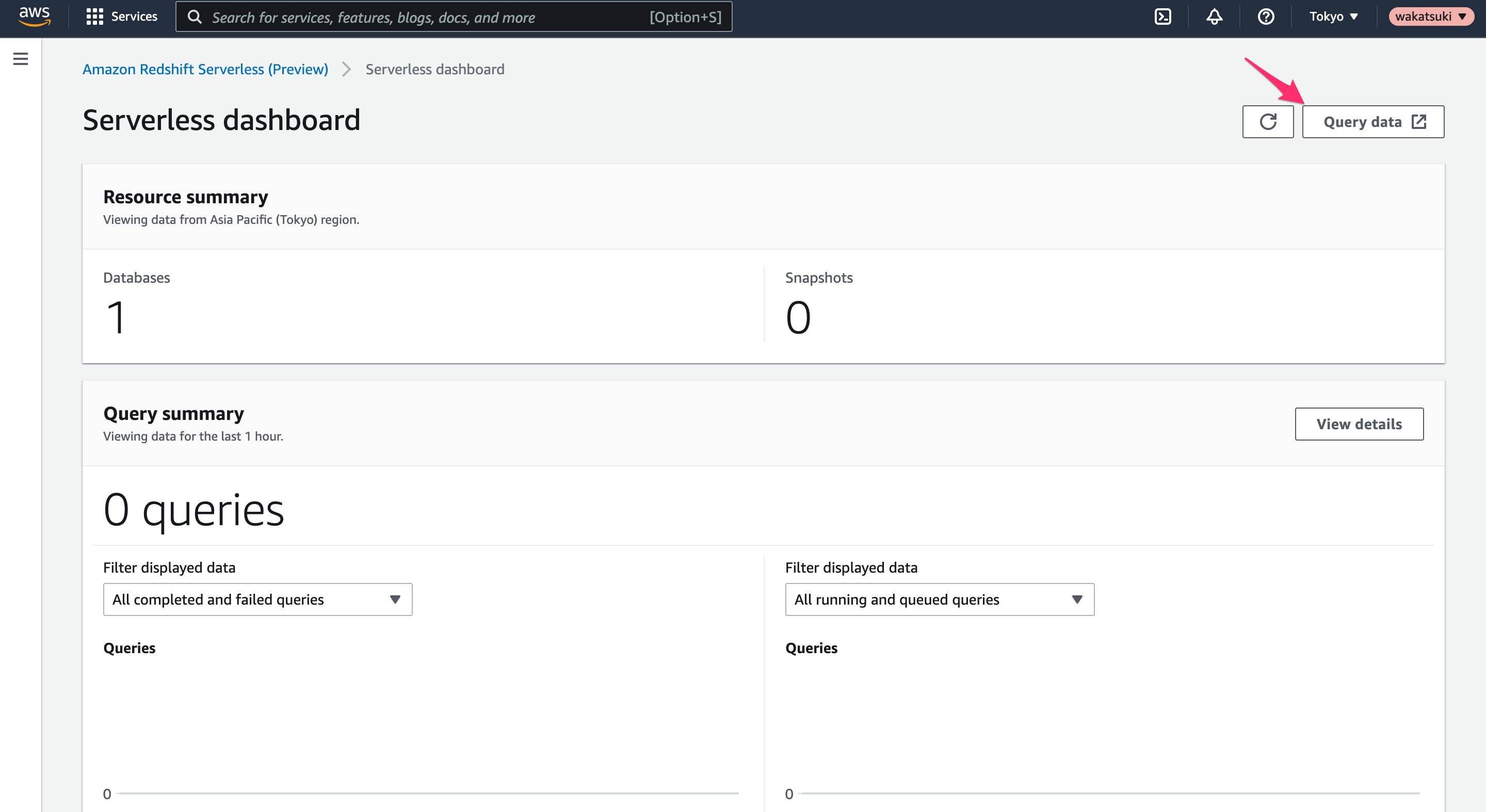
するとRedshift query editor v2のエディターが開きます。左サイドバーで[Serverless]-[sample_data_dev]-[ticket]で[Open sample queries]をクリックします。
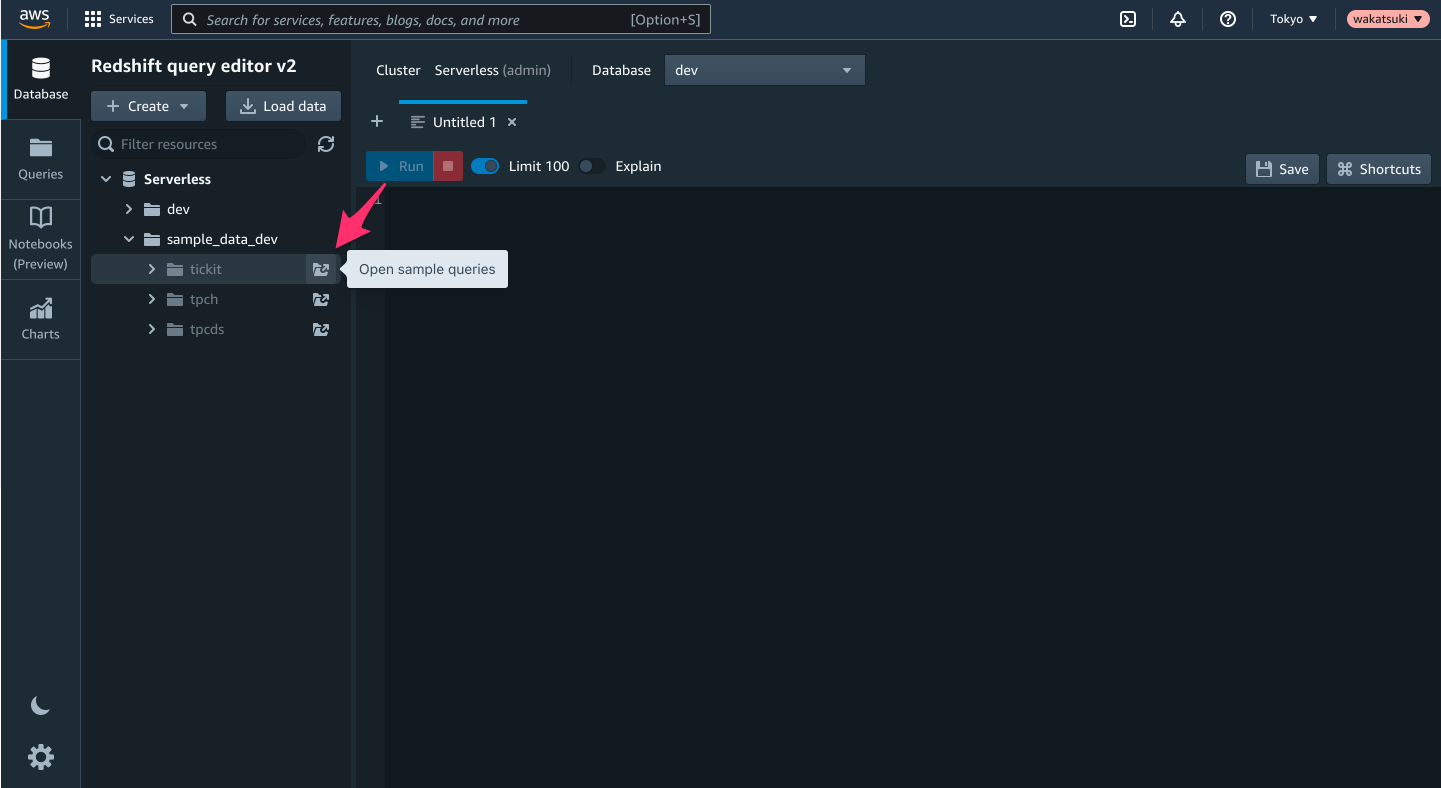
サンプルデータベースの作成を促されます。[Create]をクリックします。
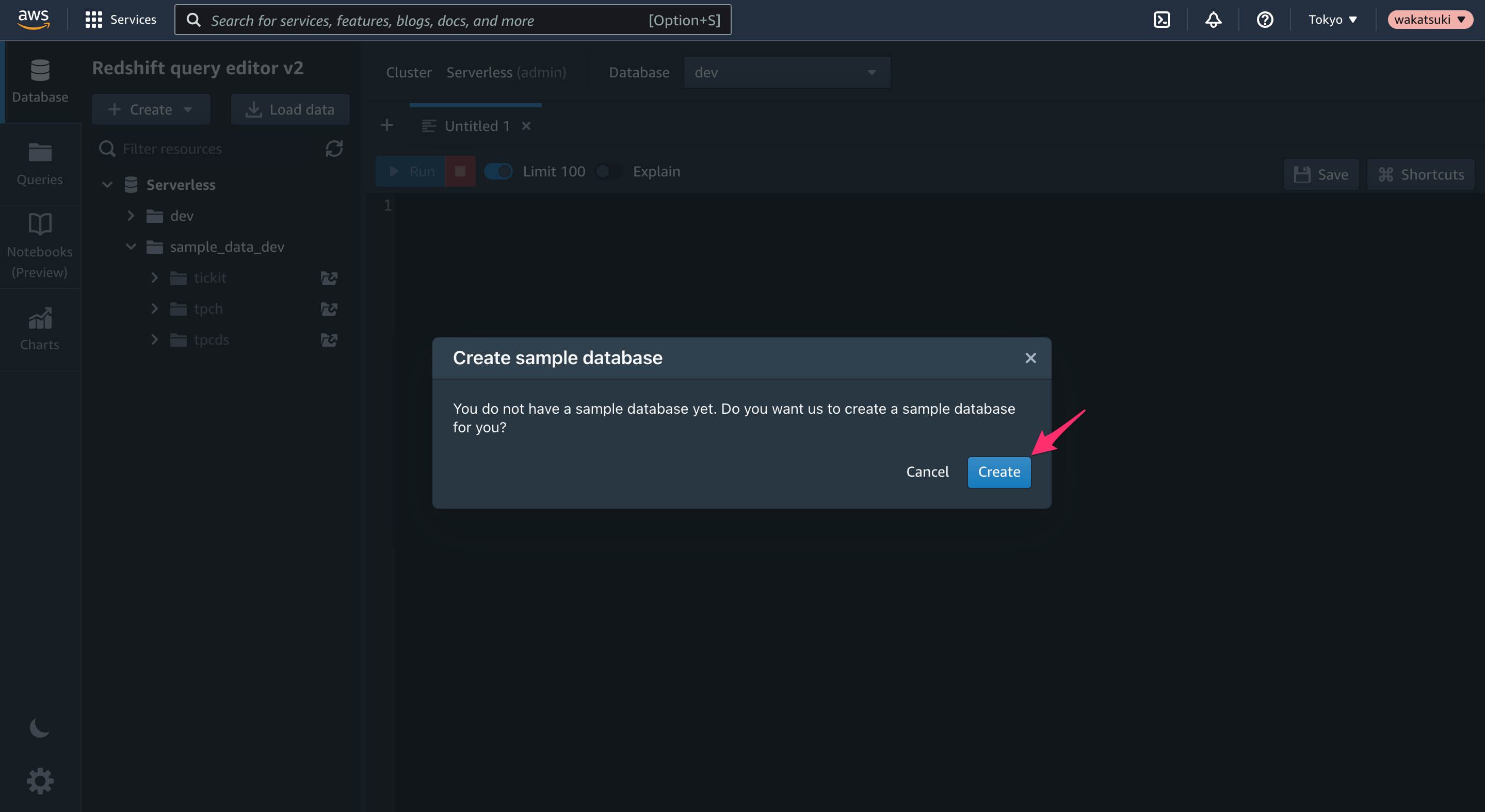
作成が行われ、完了するとエディターのタブでいくつかクエリが作成されます。
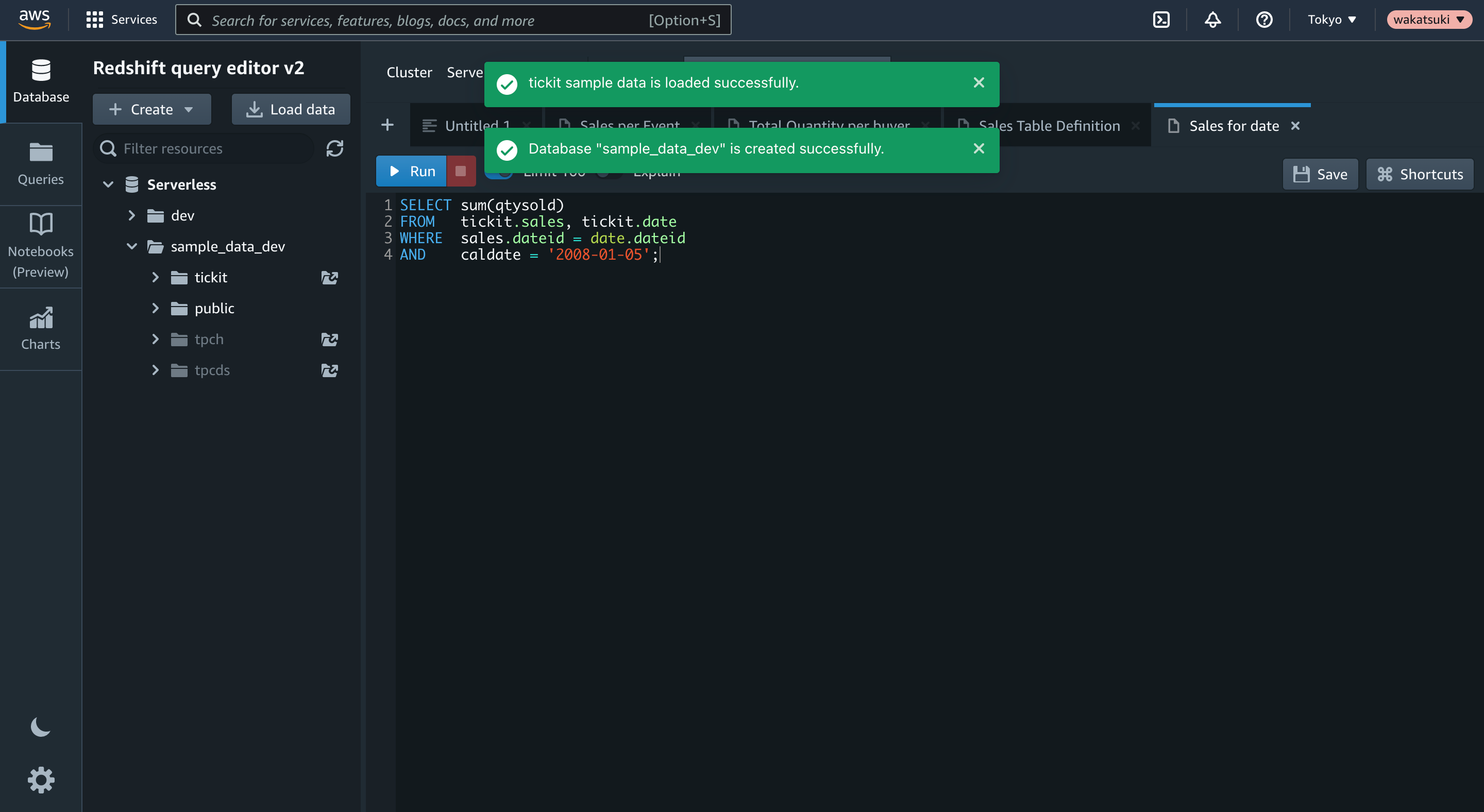
Sales for dateタブで[Run]をクリックするとクエリ実行結果が取得できました。
SELECT sum(qtysold) FROM tickit.sales, tickit.date WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
また作成されたクエリは[Queries]タブに保存されています。

グラフの表示
エディターで先程のサンプルテーブルに対して次のようなクエリを実行してみます。
SELECT * FROM tickit.sales
データが取得できました。

ここで[Chart]のトグルをオンにします。
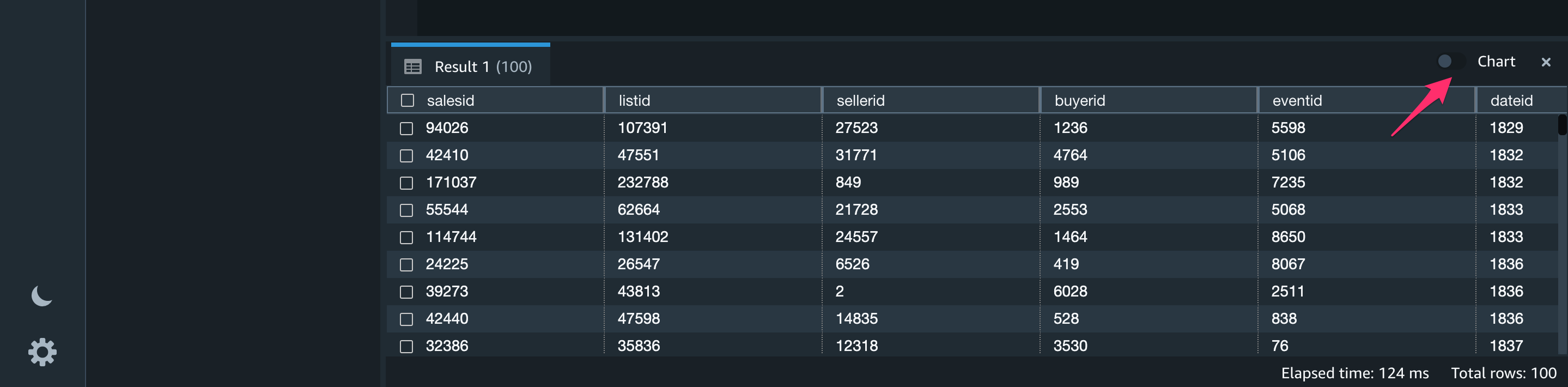
グラフが表示できました。

グラフのタイプ(Trace Type)は様々なものが選べます。

また[Save chart]をクリックすると名前を付けてグラフを保存できます。
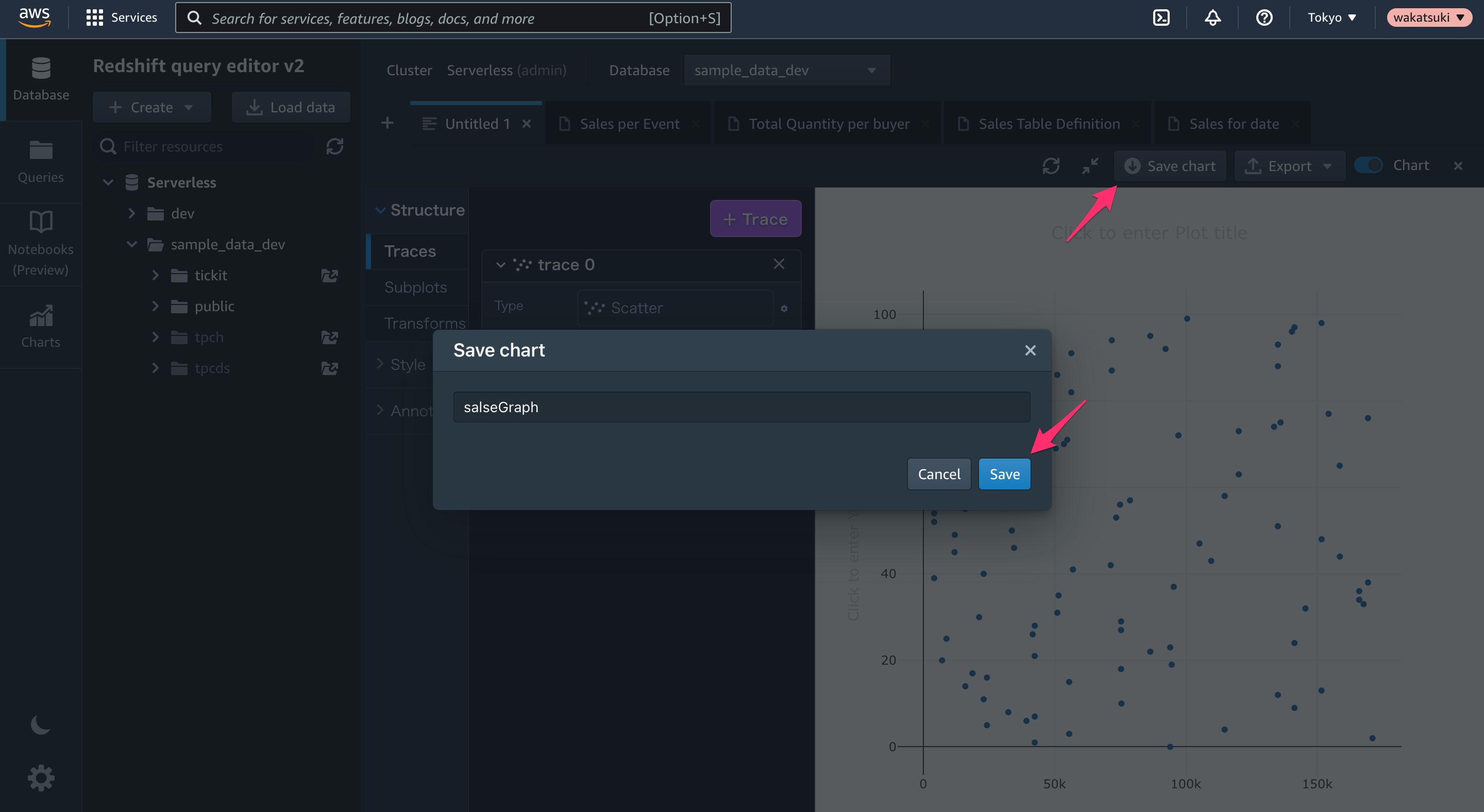
[Charts]タブで保存したグラフを確認できるようになりました。
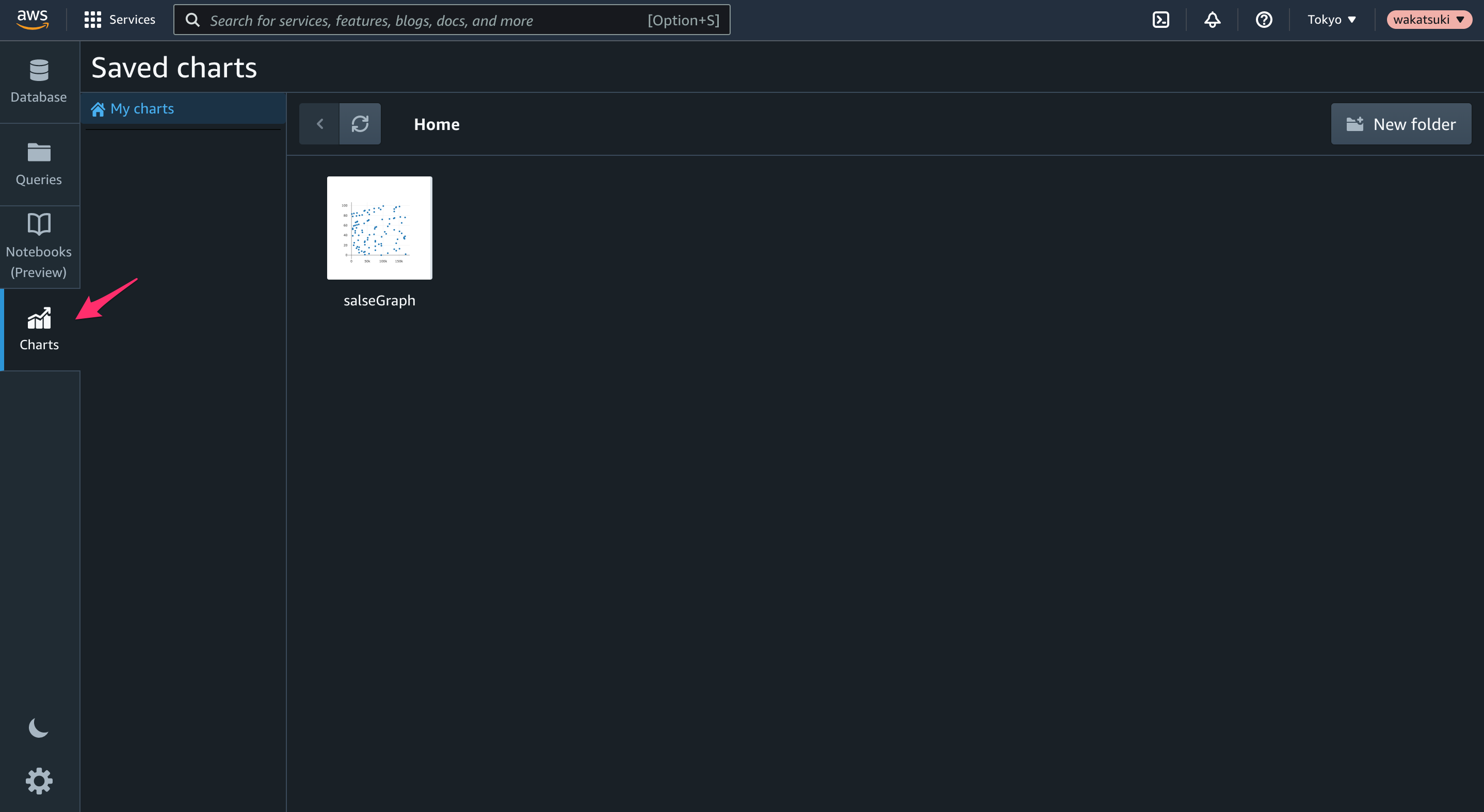
Notebooks
[Notebooks]タブは、はじめよく分からなかったのですが、クエリなどを整理してチームメンバーと共有できる機能のようです。

Amazon Redshift は、Amazon Redshift Query Editor V2 の SQL Notebooks (プレビュー) のサポートにより、複数の SQL クエリの整理、ドキュメント化、共有を簡素化します。新しい Notebooks のインターフェイスにより、データアナリストやデータサイエンティストなどのユーザーは、複数の SQL クエリや注釈を 1 つのドキュメントに整理して、より簡単にクエリを作成することができます。また、Notebooks を共有して、チームメンバーと共同作業を行うこともできます。
高度な分析を行うデータユーザーは、一度に複数のクエリを実行し、データ分析のためにさまざまなタスクを行います。Query Editor V2 では、関連するクエリをフォルダにまとめて保存したり、複数のステートメントを持つ保存された 1 つのクエリにまとめたりして整理することができます。Notebooks は、データ分析に必要なすべてのクエリを、SQL セルを使って 1 つのドキュメントに埋め込む代替的な方法を提供します。Notebooks は、Query Editor V2 で保存したクエリを共有する方法と同様に、チームメンバーと共有することができます。作業を正確にドキュメント化することで、他のユーザーとの共同作業が可能になります。Markdown セルを使用すると、作業に詳細なコンテキストを含めることができ、最も複雑なデータ分析タスクでの作業であっても、他の人の学習の負担を軽減することができます。
S3バケットからのロード
エディターではS3バケットからのデータのロードも可能です。この機能はまた別の機会に試してみたいと思います。

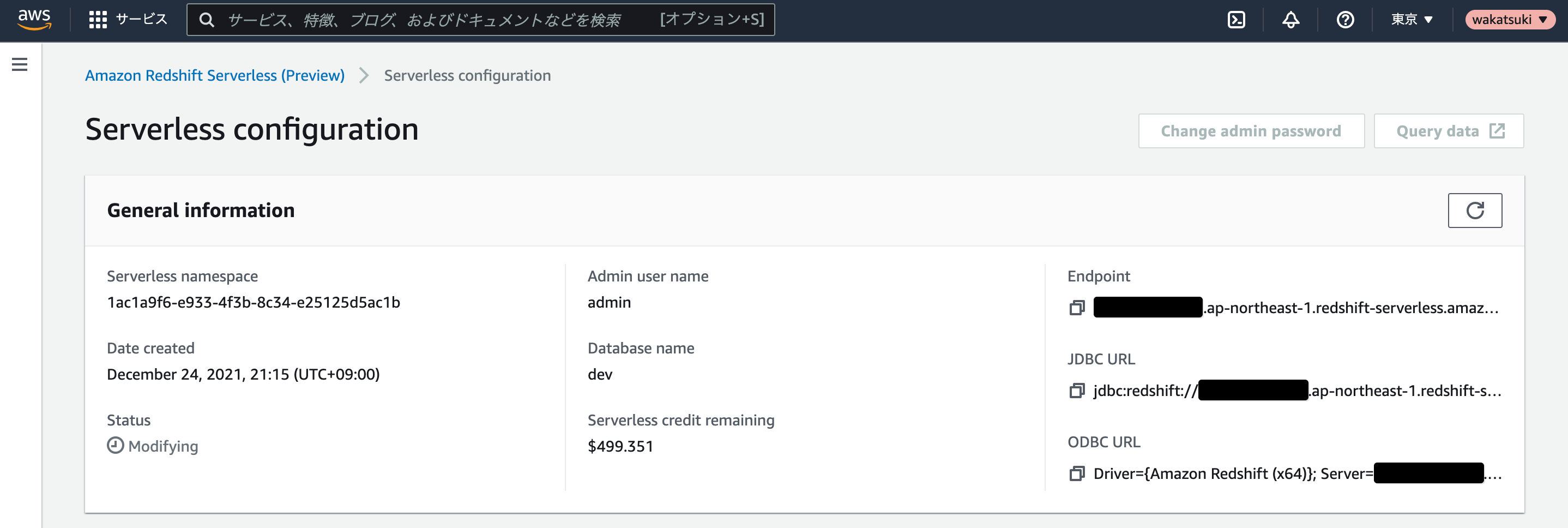
クレジットの消費状況
サーバーレスクレジットの消費状況は[Serverless configuration]から確認できます。今回くらいの使い方だと1$も消費されておらずまだまだ使えますね。
おわりに
Amazon Redshift Serverless(プレビュー)を触ってみました。
私はRedshiftは今まで触ったことが無かったのですが、サーバーレスが出たとのことで今回思い切って触ってみました。クラスターなどのインフラ部分をまったく意識することなく環境が作れたので、マネージドなAWSサービスばかり使ってきた私からしては今後の採用のハードルがグッと下がったように思います!
参考
- Redshiftの新しい「クエリエディタ V2」を使ってみた | DevelopersIO
- re:Invent 2021で登場したRedshift Serverlessを利用してみた - estie inside blog
以上










